
DATA ANALYSIS CAPSTONE PROJECT
A BIG data Analysis on love, marriage, and INFIDELITY
SUMMARY
Evaluating extramarital affairs is important due to the wide scale of partners and families that are impacted by them daily in the United States. Over the course of two months, our group of 4 researched, analyzed, and presented about extramarital affairs. Our overarching goal was to create a model that classifies any stranger as a cheater or not based on simple questions. Solving this question teaches people about their current relationships and find future partners.
SCOPE
Role: Researcher, Coder, Graphic Designer
Date: October 2016 - December 2016
Skills: Coding, Research, Data Analysis, Graphic Design
Tools: MATLAB, Google Docs, Google Slides
Deliverable: Data analysis model and poster presentation
PROCESS
DISCOVERING A PROBLEM
Before our group formed, we all individually researched big data sources and how we could analyze them. Websites like Kaggle and Kdnuggets provide large data open to the public. Once our group had formed, we realized we wanted to pursue a topic different than everyone else. We found a large dataset with a lot of features about speed dating; however, we were unable to use that dataset. This sparked the topic of love and one of our group members found a bountiful dataset from Yale's survey in 1977 about extramarital affairs. Although the data is older, we wanted to analyze this dataset in order to better understand the trend of increasing divorces over the year. The dataset can be in Table F18.1 here.
After dissecting the dataset, we had to decide what questions we wanted to solve with the questions. Our group decided on three sub questions that overarching answer the question in the red box. The sub questions are as follows:

- Are there patterns of infidelity between couples based off aspects of their long-term relationships?
- Are there are any particular aspects of marriage where infidelity seems to occur more frequently?
- Can we find the best model for accurately determining whether an individual has engaged in an affair?
DEFINING THE ANALYSIS ROUTE

The challenge in data analysis and modeling is deciding the route to analyze. From our group's toolset, we were able to choose between clustering (unsupervised grouping), regression (supervised prediction), PCA (data visualization), and classification(supervised grouping). Because we wanted to separate the cheaters and the non-cheaters in our dataset, we needed to be able to set a standard that the algorithm could learn from to classify new individuals. This meant a supervised grouping analysis, or classification. We had to preprocess our data into MATLAB in order for it to be able to be used. I lead this coding aspect of the project which included inputting and labeling the data with regards to each variable we were using as well as between cheaters vs non-cheaters.
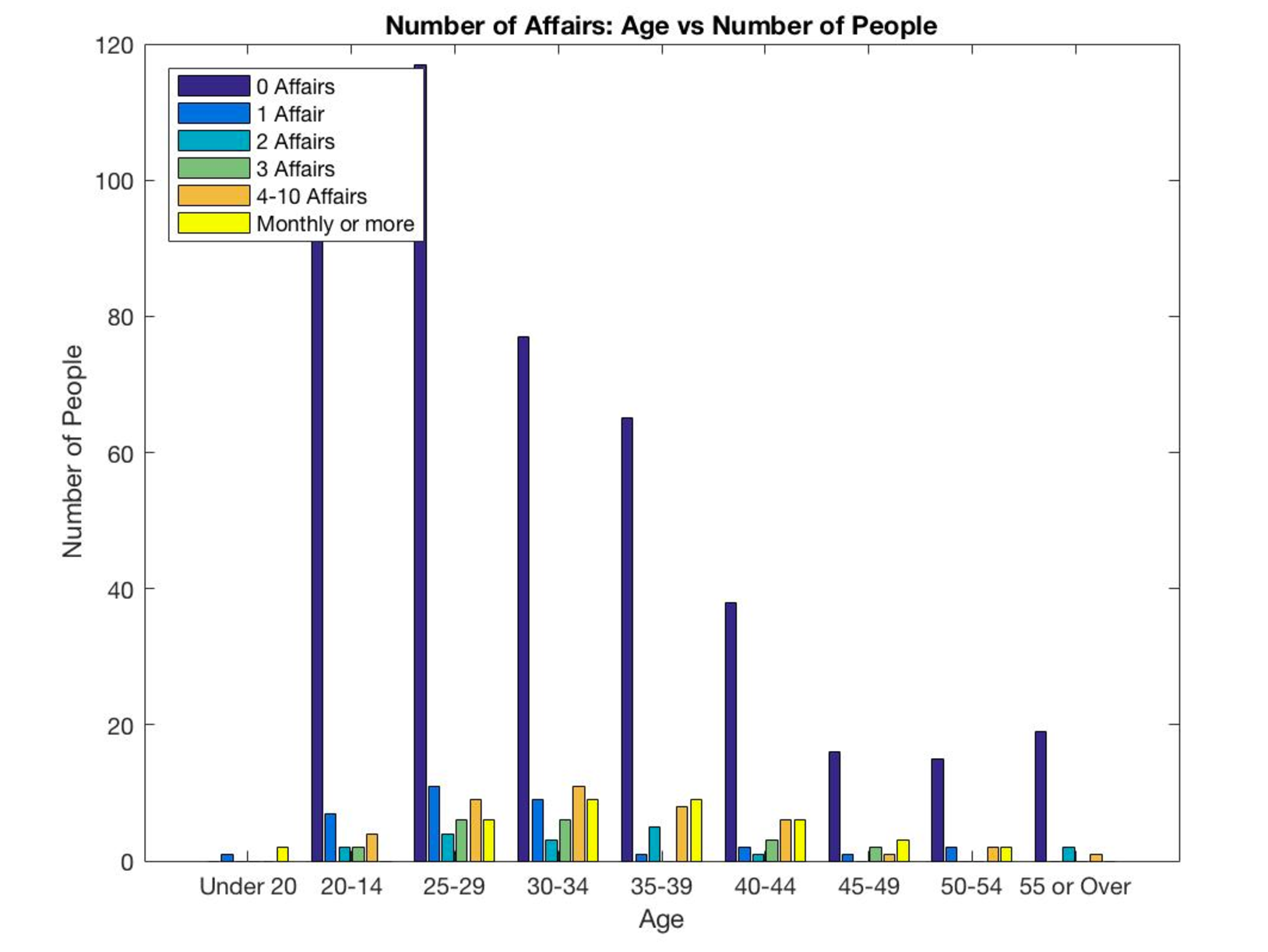
Even though graphing three-dimensional data in two-dimensions is difficult, the optimal way of visualizing the data was using color as our third dimension on the two-dimensional graph. This required a high attention to detail because preparing each variable for the bar chart takes a lot of re-organization of data. One of my team members lead this coding aspect of the project.
Variable Model Prediction Percentage
The final step to be able understand the data was to use a neural network in order to create a model that would be able to classify a person as a cheater or not. MATLAB has feature where if you input the data, it will create a neural network model that works. We spent 10 hours one day figuring out the best type of model. We used neural network clustering to see which variables out of the eight input variables were correlated. Four of the eight variables were independent on each other.
Our hope was that the four independent variables would affect the neural network's prediction more heavily; however, as seen in this bar graph, the most accurate model was using the all variables model, or the most information on a certain invididual.
DESIGNING OUR POSTER
After we had analyzed the data and come to an answer, we had to design the poster to present to our class. Even though I could do this graphic design in Adobe InDesign, I suggested using Google Slides so that all four group members could access and edit the project at any time. We had decided to all come up with our own designs, and then choose the best design out of the four. Over one weekend, I designed the following design. When our group met virtually to edit the poster, all of my group members enjoyed my design and thought it had elegant flow as well as showed our thought process smoothly.

PRESENTING THE RESULTS

At the class presentation, each person had to present our research to a group of people. My Teaching Assistant at the time was very intrigued by the final results of our project, asked me multiple questions, and commented on how fluid I was as a speaker.
To answer our initial questions, the bar graphs show that there were no discernable patterns between cheaters and non-cheaters, and we can classify an individual to be a cheater or not based on using all eight variables around 80% of the time. This means that if we received all input information from a stranger, we could classify them as someone who has engaged in infidelity at a C+ accuracy rate.
IMPACT
Our project presents a data-based approach to figuring out love and why people engage in extramarital affairs. Although our dataset was older, we were able to create a model that could classify people as cheaters. If we could gain more modern data regarding information about dating sites like Tinder or eHarmony, our project could aid in understanding people's love life using a learning algorithm. Similar to Tinder and eHarmony, our model would be able to assist people in choosing partners who won't engage in extramarital affairs.